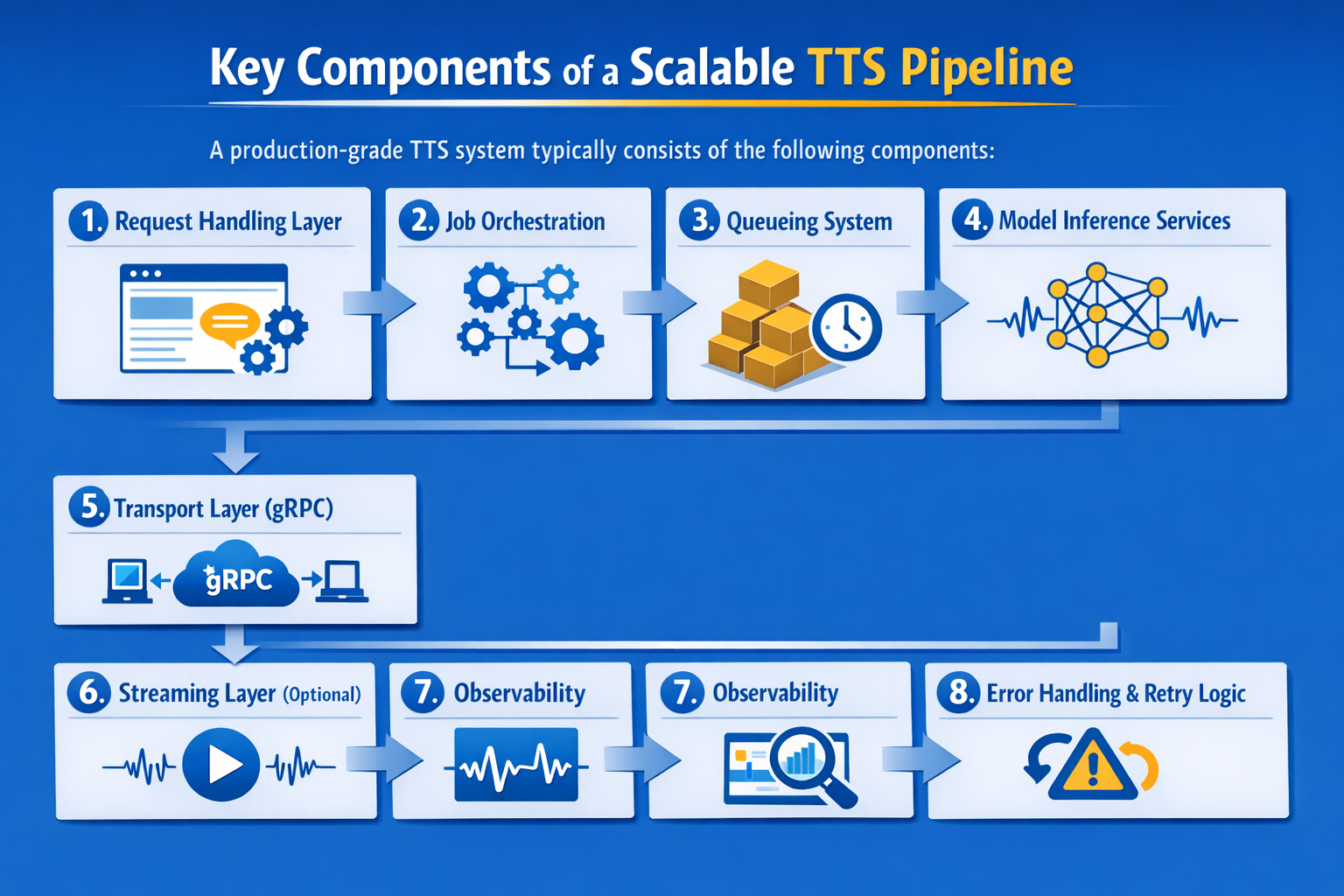
Code Examples for Each Component
1. Async Request Handler (Python - FastAPI)
import asyncio
from fastapi import FastAPI
app = FastAPI()
job_queue = asyncio.Queue()
@app.post("/synthesize")
async def synthesize(text: str):
job_id = f"job-{id(text)}"
await job_queue.put({"id": job_id, "text": text})
return {"job_id": job_id, "status": "queued"}
async def worker():
while True:
job = await job_queue.get()
try:
await process_job(job)
finally:
job_queue.task_done()
Code Description
- FastAPI receives synthesis requests, assigns a job ID, and places each request into an asynchronous in-memory queue.
- The handler returns immediately with queued status, allowing request intake without waiting for TTS generation to finish.
- An asyncio worker continuously pulls queued jobs and processes them in the background for non-blocking task execution.
- task_done() marks each queue item complete, helping track progress and maintain reliable asynchronous job handling.
2. Queue Worker
import asyncio
async def worker():
while True:
job = await fetch_job()
await process_job(job)
async def process_job(job):
audio = await call_tts_service(job["text"])
await store_result(job["id"], audio)
Code Description
- The worker continuously fetches queued jobs, enabling background processing without blocking the main application request flow.
- Each job is passed to a processing function that sends text to the TTS service for audio generation.
- Generated audio is stored against the job ID, making results available for later retrieval or delivery.
- This pattern separates request intake from heavy processing, improving scalability and keeping the system responsive.
3. gRPC Service Definition (Protobuf)
syntax = "proto3";
service TTSService {
rpc Synthesize (TTSRequest) returns (TTSResponse);
rpc StreamSynthesize (TTSRequest) returns (stream AudioChunk);
}
message TTSRequest {
string text = 1;
}
message TTSResponse {
bytes audio = 1;
}
message AudioChunk {
bytes chunk = 1;
}
Code Description
- This Protocol Buffers definition describes the TTS service contract, including standard synthesis and streaming audio response methods.
- Synthesize returns the full generated audio in one response for simpler request-response TTS workflows.
- StreamSynthesize sends audio in chunks, enabling lower perceived latency and earlier playback for long responses.
- The message schema defines how text requests and binary audio data are exchanged between gRPC clients and servers.
4. gRPC Server (Python)
import grpc
from concurrent import futures
import tts_pb2, tts_pb2_grpc
class TTSService(tts_pb2_grpc.TTSServiceServicer):
def Synthesize(self, request, context):
audio = generate_audio(request.text)
return tts_pb2.TTSResponse(audio=audio)
def serve():
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
tts_pb2_grpc.add_TTSServiceServicer_to_server(TTSService(), server)
server.add_insecure_port('[::]:50051')
server.start()
server.wait_for_termination()
Code Description
- This gRPC server exposes the TTS synthesis method and handles incoming requests using a thread pool for concurrency.
- The Synthesize method receives input text, generates audio, and returns the result as a binary response.
- The server listens on port 50051, making the TTS service available to internal clients or workers.
- This setup supports scalable service-to-service communication with lower overhead than typical HTTP-based internal APIs.
5. gRPC Client
def call_tts(text):
channel = grpc.insecure_channel("localhost:50051")
stub = tts_pb2_grpc.TTSServiceStub(channel)
try:
response = stub.Synthesize(
tts_pb2.TTSRequest(text=text),
timeout=5.0
)
return response.audio
except grpc.RpcError as e:
print(f"gRPC call failed: {e.code()} - {e.details()}")
return None
Code Description
- This client connects to the gRPC TTS service and sends text for audio generation through a typed service stub.
- A timeout protects the call from hanging indefinitely when the TTS service is slow or unavailable.
- On success, the client returns the generated audio bytes for storage, streaming, or playback.
- Basic error handling captures gRPC failures and prevents the calling service from crashing unexpectedly.
6. Streaming Example
class TTSService(tts_pb2_grpc.TTSServiceServicer):
def Synthesize(self, request, context):
audio = generate_audio(request.text)
return tts_pb2.TTSResponse(audio=audio)
def StreamSynthesize(self, request, context):
for chunk in generate_audio_chunks(request.text):
yield tts_pb2.AudioChunk(chunk=chunk)
Code Description
- This service supports both full-response synthesis and chunked streaming for different TTS delivery patterns.
- Synthesize generates the complete audio output first, then returns it in a single response message.
- StreamSynthesize yields audio chunks progressively, allowing playback to begin before full synthesis completes.
- This dual approach improves flexibility for systems balancing simplicity, latency, and real-time user experience.
7. Observability Hook
import time
import logging
logger = logging.getLogger(__name__)
def timed_tts_call(text, job_id):
start = time.perf_counter()
try:
audio = call_tts(text)
duration = time.perf_counter() - start
logger.info("tts_call_success job_id=%s latency=%.3fs", job_id, duration)
return audio
except Exception as e:
duration = time.perf_counter() - start
logger.error("tts_call_failed job_id=%s latency=%.3fs error=%s", job_id, duration, str(e))
raise
Code Description
- This wrapper measures TTS call duration, helping track latency for each synthesis request in production environments.
- Successful calls are logged with job ID and execution time for monitoring performance and tracing request flow.
- Failed calls record latency and error details, making troubleshooting easier during service disruptions or inference issues.
- This pattern improves observability by turning each TTS request into measurable operational telemetry.