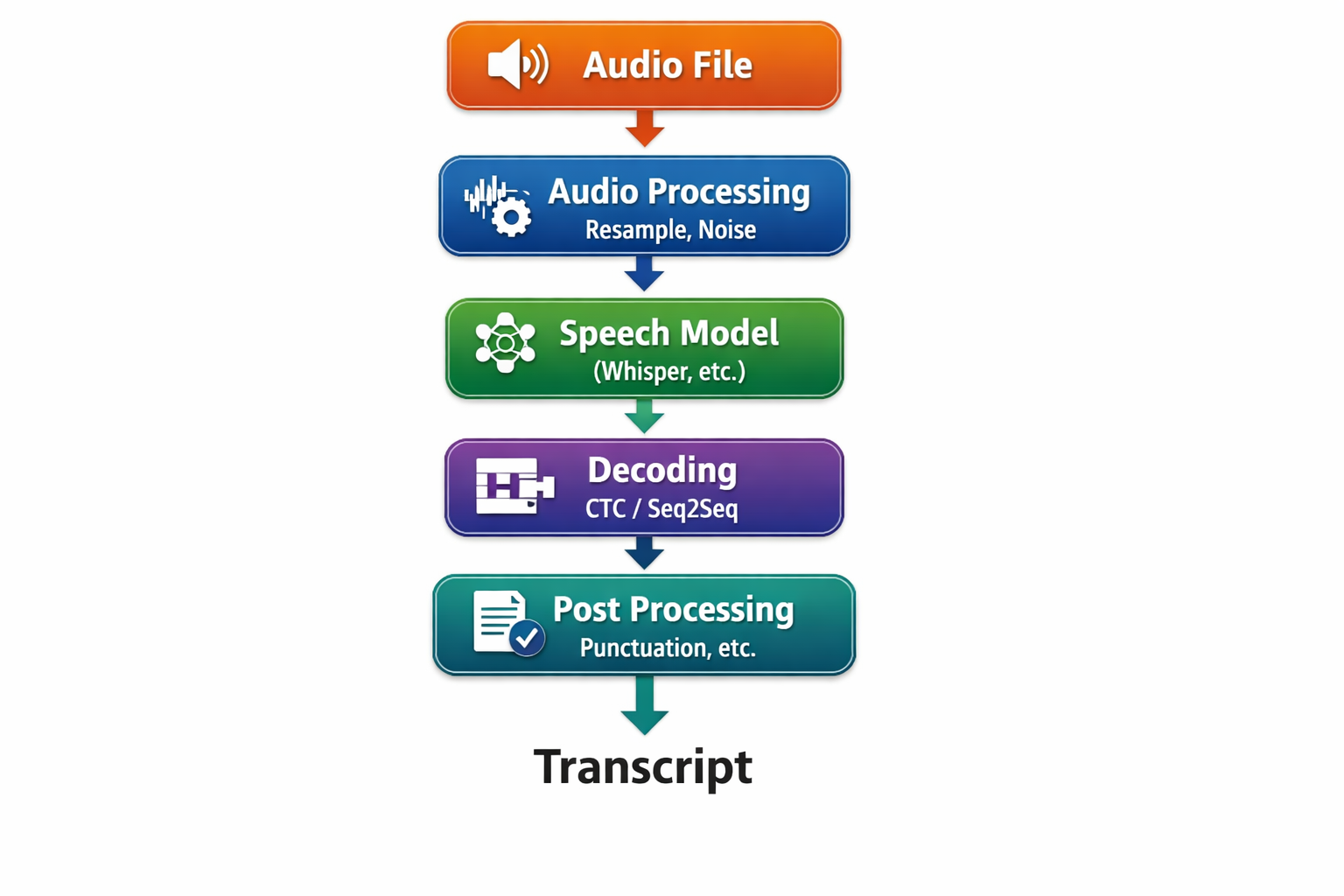
Popular Open Source Speech-to-Text Models
Several high-quality open-source STT models are available through Hugging Face and related ecosystems.
1. Whisper
Whisper (openai/whisper-large-v3) is one of the most widely used open-source speech recognition models. It’s designed for automatic speech recognition (ASR) and speech translation, and it’s known for being robust in real-world audio—especially when recordings include background noise, varied accents, or multiple languages.
Because it was trained on a very large and diverse multilingual dataset, Whisper tends to generalize well across different domains and recording conditions. This makes it a strong default starting point for many STT applications, particularly when you want solid accuracy out of the box without heavy tuning
Whisper’s strengths include strong multilingual accuracy, resilience to background noise, and good handling of different accents, with multilingual and translation capabilities built into the model family. The main trade-offs are that it can be relatively compute-heavy, long audio typically needs chunking/segmentation to run efficiently, and it may be slower than some CTC-based models in low-latency setups
+ Home Page: OpenAI Whisper
+ GitHub: Github Page: Whisper
+ Hugging Face: HuggingFace Whisper
2. Distil-Whisper
Distil-Whisper (distil-whisper/distil-large-v3) is a compressed version of the Whisper model created using knowledge distillation. The goal of this approach is to preserve much of Whisper’s transcription accuracy while significantly reducing model size and computational requirements. By training a smaller model to mimic the outputs of the larger Whisper model, Distil-Whisper provides a more efficient alternative for many real-world deployments.
Because it is lighter and optimized for performance, Distil-Whisper is particularly useful in environments where latency, GPU availability, or infrastructure costs are important considerations. It maintains compatibility with many Whisper-based pipelines, meaning existing workflows built around Whisper can often adopt Distil-Whisper with minimal modification.
The strengths of Distil-Whisper include faster inference speeds, a smaller memory footprint, and compatibility with Whisper tooling and pipelines. However, there are some trade-offs: the distilled model may show slightly lower transcription accuracy, and performance can vary depending on the language and acoustic conditions.
For teams building scalable speech-to-text systems, Distil-Whisper is often preferred when cost efficiency and response time matter more than achieving the absolute highest accuracy.
+ HuggingFace Home Page: Hugging Face Distil-Whisper overview
+ GitHub: Distil-Whisper project
3. Wav2Vec2
Wav2Vec2 (facebook/wav2vec2-base-960h) introduced a powerful self-supervised learning approach for speech recognition. Instead of relying entirely on labeled datasets, the model learns meaningful speech representations from large amounts of unlabeled audio. After this pretraining phase, the model can be fine-tuned for automatic speech recognition (ASR) tasks using smaller labeled datasets. This approach significantly reduced the amount of annotated data required to build high-quality speech recognition systems.
Because Wav2Vec2 uses CTC (Connectionist Temporal Classification) decoding, it tends to be efficient and relatively lightweight compared with some sequence-to-sequence models. It also benefits from a strong ecosystem within the research and developer community, with many fine-tuned variants available for different languages, accents, and domain-specific datasets.
The strengths of Wav2Vec2 include efficient decoding with low latency, broad ecosystem support, and a wide range of pretrained and fine-tuned models available through open-source repositories. However, it has some limitations. Compared with models like Whisper, Wav2Vec2 can be less robust to background noise and complex acoustic environments, and punctuation or formatting usually needs to be added through post-processing steps.
Despite these trade-offs, Wav2Vec2 remains a strong option when organizations want to fine-tune speech recognition models for domain-specific datasets, such as call centers, medical dictation, or specialized vocabulary.
+ Home Page: Wav2Vec Home Page
+ HuggingFace Home Page: Hugging Face Wave2Vec
+ GitHub: Wave2Vec GitHub
4. HuBERT
HuBERT (facebook/hubert-large-ls960-ft) is a self-supervised speech representation model developed by Meta AI. HuBERT stands for Hidden Unit BERT, and it builds on ideas similar to Wav2Vec2 but introduces a different training strategy. Instead of directly predicting raw audio features, HuBERT learns to predict clustered hidden units derived from speech signals, allowing the model to capture deeper and more structured representations of speech.
Through this approach, HuBERT learns rich acoustic representations from large amounts of unlabeled audio data, which can then be fine-tuned for downstream tasks such as automatic speech recognition (ASR). This design makes it particularly valuable for research environments and for organizations that want to train models on specialized speech datasets.
HuBERT’s strengths include strong speech representation learning, competitive ASR performance after fine-tuning, and flexibility for research experimentation and domain adaptation. However, the model typically requires additional downstream processing for full transcription pipelines, and achieving the best performance often depends on fine-tuning the model with domain-specific data.
As a result, HuBERT is often chosen by teams focused on research, experimentation, or building custom ASR models tailored to specific industries or datasets.
+ Home Page: HuBERT Home Page
+ HuggingFace Home Page: Hugging Face HuBERT
+ GitHub: HuBERT GitHub