What are Embeddings and Embedding Databases
In the context of AI and natural language processing (NLP) specifically, embeddings refer to numerical representations of words, phrases, or sentences. These embeddings are designed to capture semantic meanings and relationships between words in a way that a machine learning model can understand and process.
By learning embeddings, words with similar meanings or that often appear in similar contexts are mapped to nearby points in the embedding space. This allows AI models to capture and leverage semantic relationships between words when performing tasks like language translation, sentiment analysis, or text generation.
The following example uses embeddings in the simplest form:
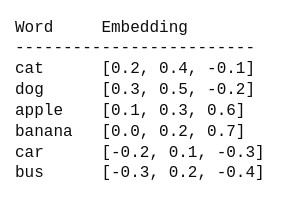
Note:> Embeddings are also known as vector embeddings
What are Embedding/Vector Databases
Embeddings databases encompass a fusion of vector indexes (sparse and dense), graph networks, and relational databases. This facilitates SQL-driven vector search, topic modeling, retrieval augmented generation, and additional functionalities.
These databases can function independently or serve as a robust knowledge repository for large language model (LLM) prompts.
Common Embedding / Vector Databases
1. ChromaDB
These databases can function independently or serve as a robust knowledge repository for large language model (LLM) prompts.
Home page: Click here
Languages Supported: Python, Javascript
Github Home page: Click here
2. FAISS (Facebook AI Similarity Search)
As the name implies, this embedding database is created by Facebook .
Home page: Click here
Languages Supported: Python
Github Home page: Click here
3. txtAI
txtAI is a vectors/embeddings database that provides semantic search, LLM orchestration and language model workflows.
Home page: Click here
Languages Supported: Python
Github Home page: Click here
Sample Code that uses txtAI Embeddings Database
Lately, I have been experimenting with txtAI. I found it to be easy to use. I have experimented with switching between different models and running benchmarks.
| Computer Specifications | |
| CPU | Intel(R) Core(TM) i7-7500U CPU @ 2.70GHz |
| CPU MHz | 3500 |
| Cache Size | 4096 KB |
| Memory Size | 16 GB |
Installation of Python Library
pip install txtai
or
pip3 install txtai
The following code will instantiate txtAI object and will take statistics for object instantiation, model load, and search time.
from txtai import Embeddings
topics = [
“Nissan Toyota Camry are JDM”,
“JDM Japan Domestic Market cars”,
“JDM cars are fun to drive”
]
#Load the model
st = time.time()
self.txtAI_embeddings = Embeddings(path="sentence-transformers/LaBSE", content=True, objects=True)
duration = time.time() - st
print( f”Model Load time: {duration}”)
#Load the embeddings
st = time.time()
self.txtAI_embeddings.index(topics)
duration = time.time() - st
print( f”Embedding Load time: {duration}” )
#Search time
st = time.time()
question_embedding = self.txtAI_embeddings.search(question)
duration = time.time() - st
print( f”Search time: {duration}” )
Now save this code as test_aitxt.py. We can execute this code using the following command:
python3 test_aitxt.py
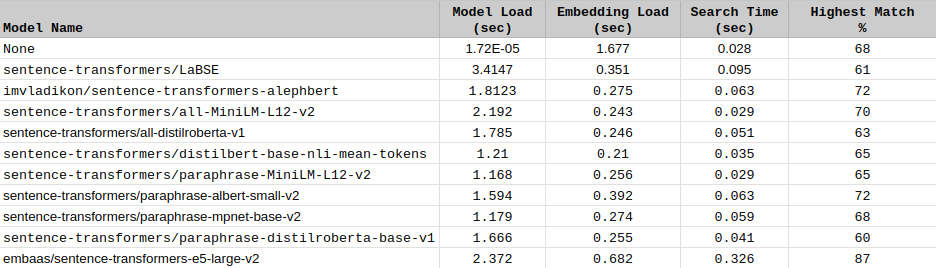
Following image tabulates the results of trying various models. You can see how results differs in terms of instantiation, model load and search times:
Conclusion
In summary, embeddings play a vital role in AI and NLP systems, enabling machines to comprehend and analyze language by representing words, phrases, or sentences numerically. These numerical representations, whether sparse or dense, capture semantic connections, thereby improving tasks such as language translation and sentiment analysis. Embeddings databases, which utilize vector indexes, graph networks, and relational databases, provide potent tools for SQL-driven vector search and knowledge storage. Leading platforms like Chroma DB, FAISS, and txtAI are at the forefront of this field.
txtAI, in particular, is noteworthy for its flexibility, facilitating smooth model switching and efficient semantic search. As we delve deeper into these technologies, embeddings and their associated databases hold the promise of propelling advancements in AI-driven language understanding and its practical applications.
How FAMRO can help your in your LLM Project?
Our Tech leaders have vast experience in LLM implementations across diverse verticals. Some of the USE Cases include:
Tele-heatlh
E-Commerce
Custom Bot Development
AI Work force development
Please don't hesitate to Contact us for free initial consultation.