Five Practical Methods to Prevent or Reduce DDoS Risk
There is no single magic fix. The most effective approach is a layered defense, where multiple controls work together.
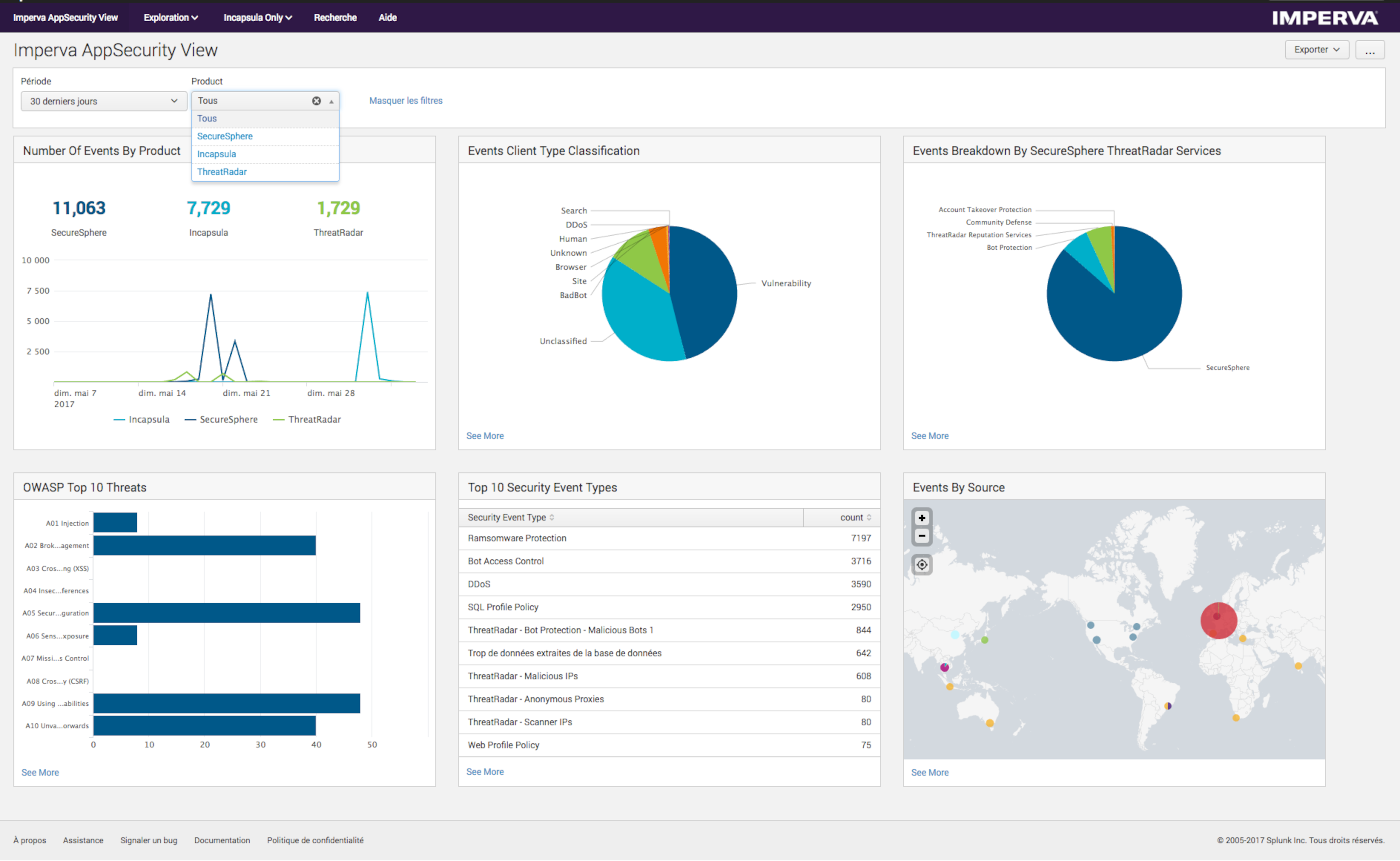
1. Traffic filtering and rate limiting
Traffic filtering helps block obviously suspicious requests before they consume too many resources. Rate limiting sets boundaries on how many requests a user, device, or IP can make within a certain period.

This is useful because many attacks rely on volume or repeated requests to the same endpoint. Rate limiting will not stop every attack, but it can reduce noise and protect critical functions like login pages, search endpoints, or API calls.
For example, if a public API normally receives 50 requests per minute from a client, but one source suddenly sends thousands, rate limits can help slow or reject that activity.
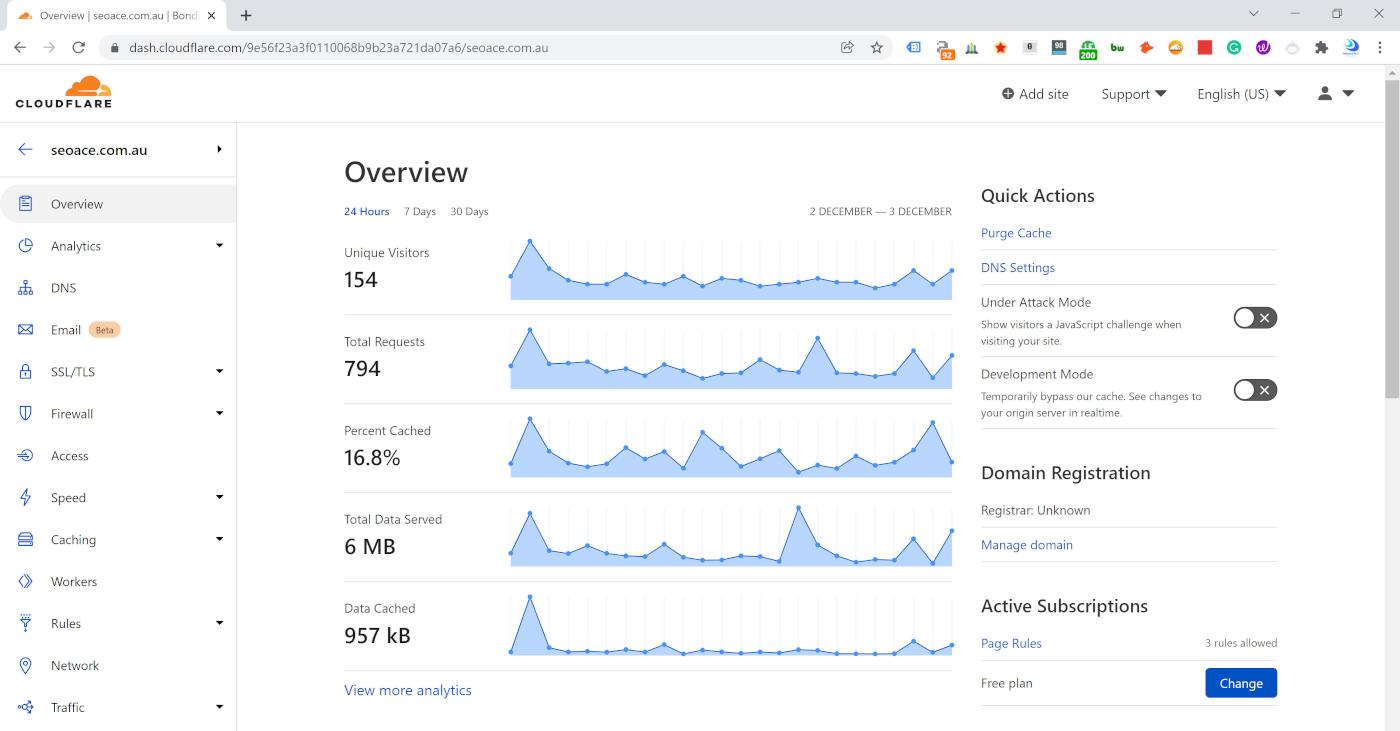
2. Content delivery networks and edge protection
A CDN can help distribute content closer to users and absorb large amounts of traffic at the network edge before it reaches your origin systems.
This matters because you do not want every request hitting your application servers directly. By using edge protection, cached content, and traffic handling services, you can reduce the load on your core platform and improve resilience during spikes.
For growing businesses, this is often one of the most practical starting points because it improves both performance and protection.
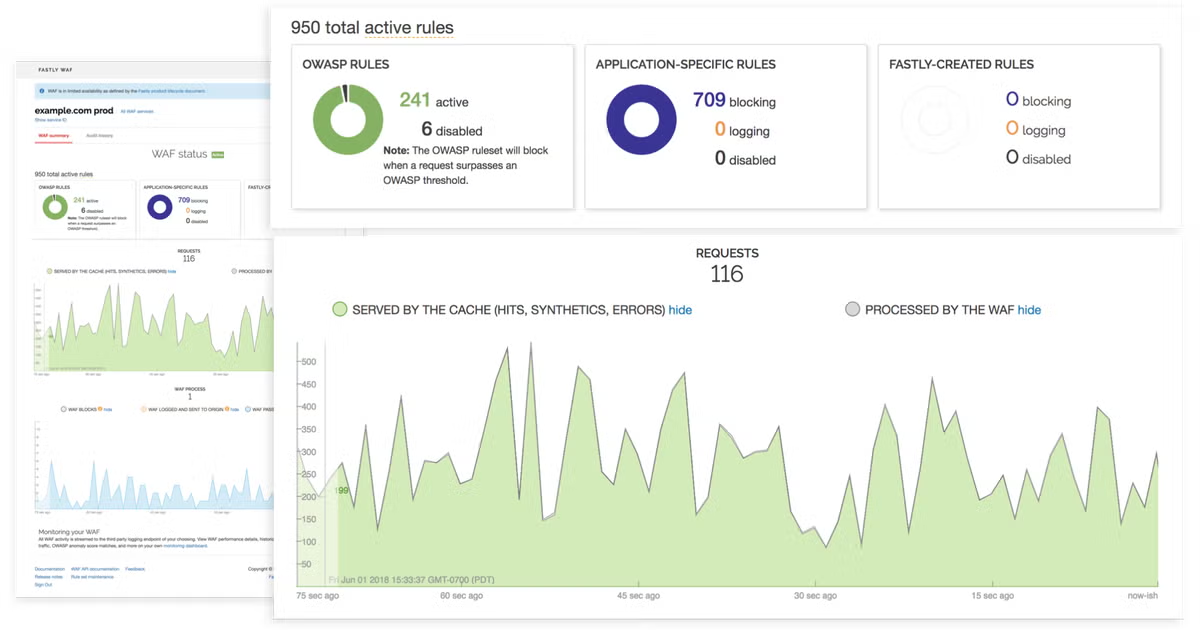
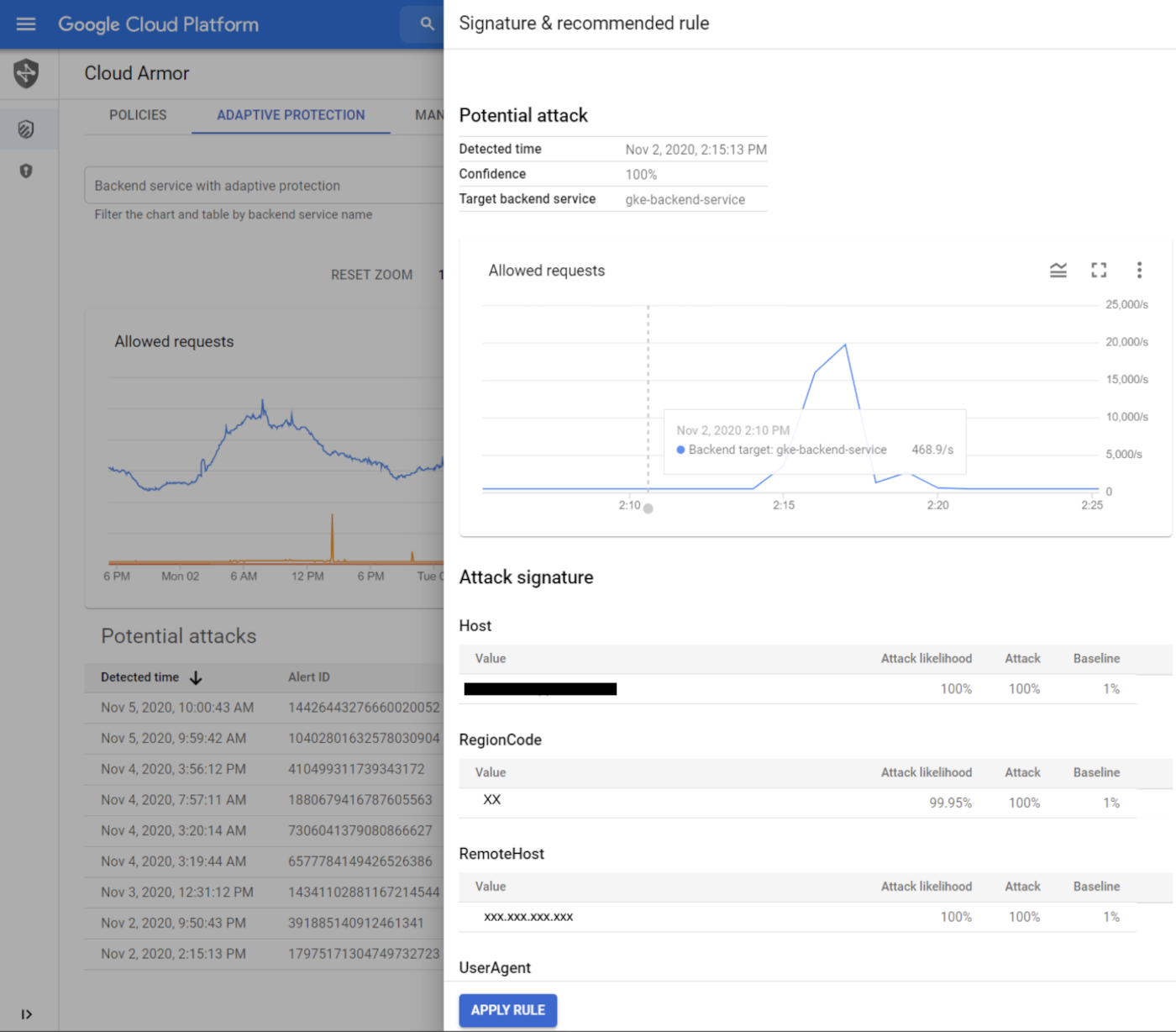
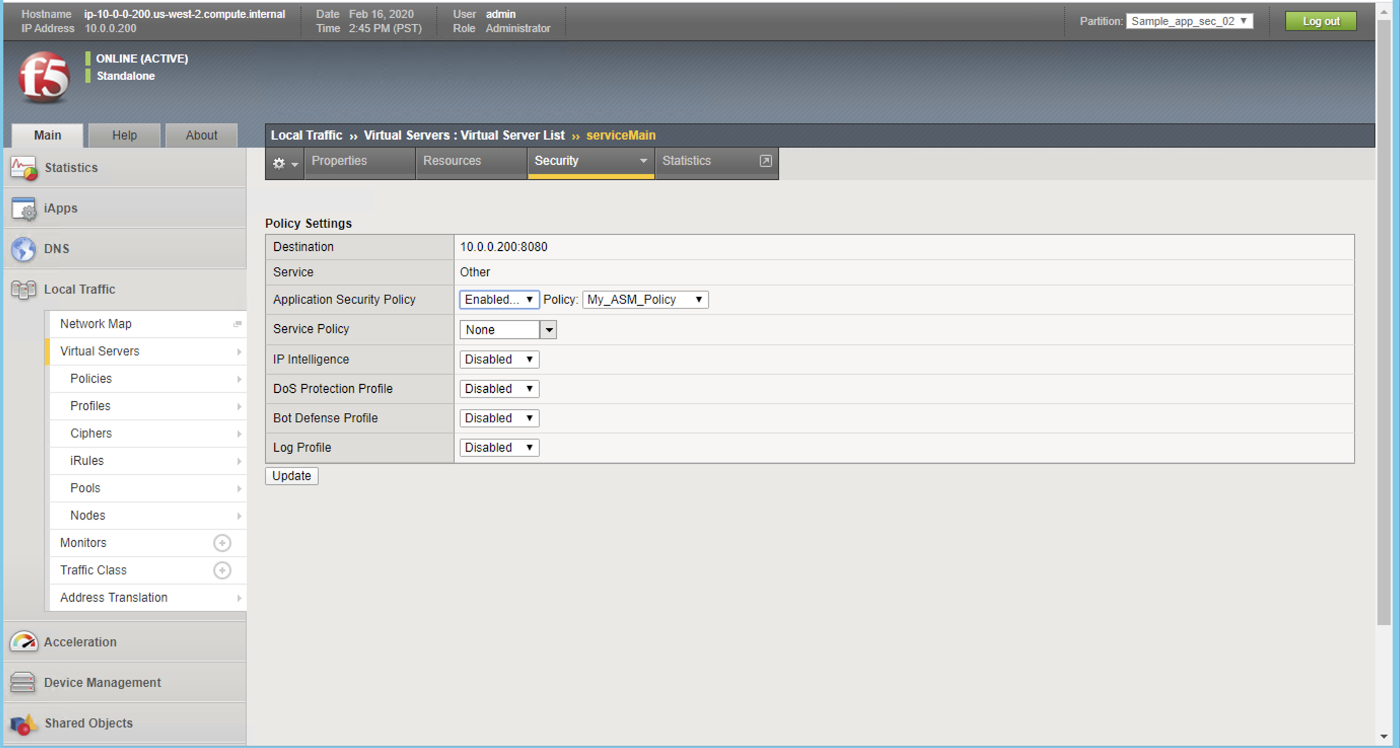
3. Web application firewalls
A web application firewall, or WAF, sits in front of web applications and inspects incoming traffic. It can help identify and block malicious patterns, suspicious requests, or attempts to abuse specific application behavior.
A WAF is not just for DDoS, but it plays an important role in layered defense. It can help distinguish legitimate user activity from behavior that looks automated or abusive, especially at the application layer.
This becomes valuable when the attack is not purely about raw volume, but about overwhelming search, login, checkout, or API endpoints in a more targeted way.
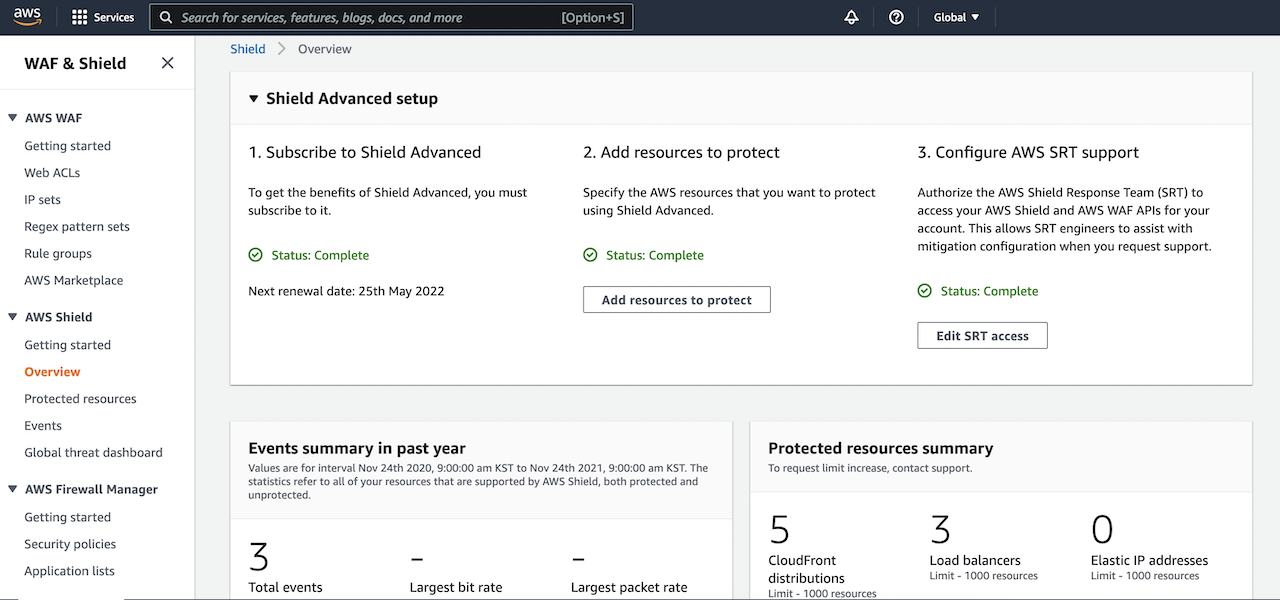
4. Network redundancy and load balancing
Redundancy means avoiding single points of failure. Load balancing spreads traffic across multiple systems so that one overloaded server does not take down the whole service.
For startups and scale-ups, redundancy does not have to mean building a huge enterprise-grade architecture overnight. It can be as practical as distributing services across zones, using multiple upstream options, and making sure key applications are not dependent on one fragile component.
The goal is simple: if one part of the environment is under pressure, the whole business should not stop.
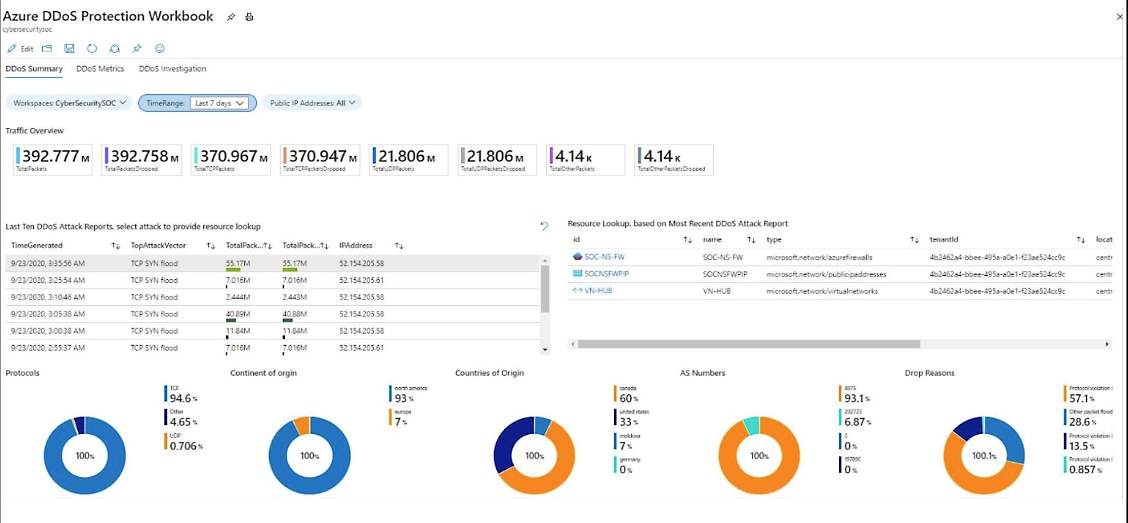
5. Incident response planning and monitoring
Technology alone is not enough. You also need a plan.
Monitoring helps detect unusual traffic patterns early. Incident response planning makes sure people know what to do when alerts start firing.
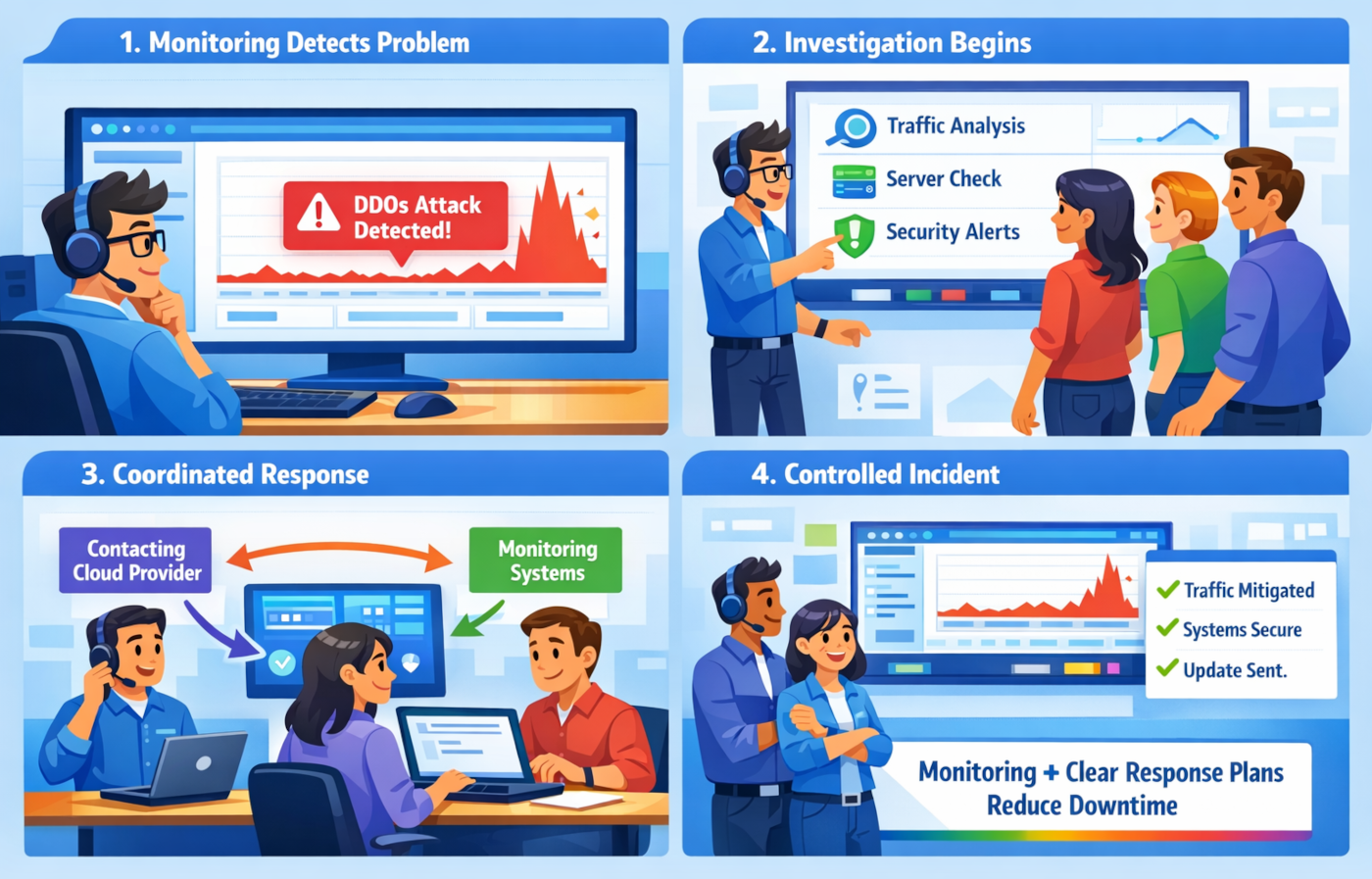
That includes questions like:
- Who investigates first?
- Who contacts cloud or network providers?
- Who updates customers?
- Which services are most critical?
- What is the escalation path if the incident continues?
A lightweight, well-practiced response plan is often far more useful than a long document nobody reads.