The Inflection Point: Three Changes That Turned Agents into Systems
1. A Common Connector Layer for Tools and Data Sources
Early agent prototypes were fragile because every “tool” connection was custom: a wrapper here, a schema mismatch there, a one-off auth pattern everywhere. Standardized tool connectivity is reducing this integration tax.
The Model Context Protocol (MCP) is explicitly designed as an open protocol to connect LLM applications to external tools and data sources in a consistent way, so teams don’t have to rebuild the same adapters for every model and backend.
Importantly for enterprises, MCP’s momentum isn’t just theoretical—industry reporting notes MCP’s growing role as a common “port” for tool integrations across major AI ecosystems and its move toward neutral governance.
Enterprise implication: standard connectors create standard controls: consistent logging, centralized allow/deny policies, and repeatable security reviews. That’s the difference between “a cool agent” and “a platform capability.”
2. Turning Agents Into Processes: State, Steps, and Guardrails
The second shift is organizational as much as technical: enterprises are replacing improvisational agent behavior with explicit orchestration patterns—state machines, graphs, retries, timeouts, and human approvals.
Frameworks such as Microsoft AutoGen popularized multi-agent conversations where different agents collaborate, optionally with human feedback in the loop.
At the same time, the ecosystem is nudging teams toward “more controlled agency,” where you model the workflow as a graph with well-defined states and handoffs (rather than letting an agent loop forever). LangGraph is positioned directly in that lane, emphasizing stateful, controllable flows and human-in-the-loop controls.
Microsoft has also started converging ideas across agent tooling—its Agent Framework is presented as a unified foundation for building and orchestrating agents and multi-agent workflows.
3. RAG 2.0: Hybrid, Graph, and Agentic Retrieval in Practice
Most enterprises adopted retrieval-augmented generation (RAG) to keep answers grounded in internal content. But “vector search over chunks” often fails in production for predictable reasons: acronyms, policy nuance, and multi-hop questions that require connecting facts across documents.
A production-default recipe is emerging: hybrid retrieval (lexical BM25 + vector embeddings) plus reranking to improve relevance and reduce “near but wrong” context. This pattern is becoming mainstream in platform docs and guidance for enterprise search and RAG.
For harder questions—where the system must connect entities, relationships, and “communities” of related content—GraphRAG is an increasingly common next step. Microsoft Research describes GraphRAG as a structured, hierarchical approach that extracts a knowledge graph from unstructured text and uses those structures to improve retrieval and reasoning.
Finally, retrieval itself is becoming “agentic”: instead of a single fetch, the system iterates—reformulating queries, consulting multiple sources, and validating evidence. LlamaIndex has framed this direction explicitly as “agentic retrieval,” treating retrieval as a tool the system uses repeatedly until it can justify an answer.
Enterprise implication: “RAG 2.0” is not one technique; it’s an operating posture. Retrieval becomes a subsystem with SLOs, tuning, evals, and traceability—because you can’t manage what you can’t measure.

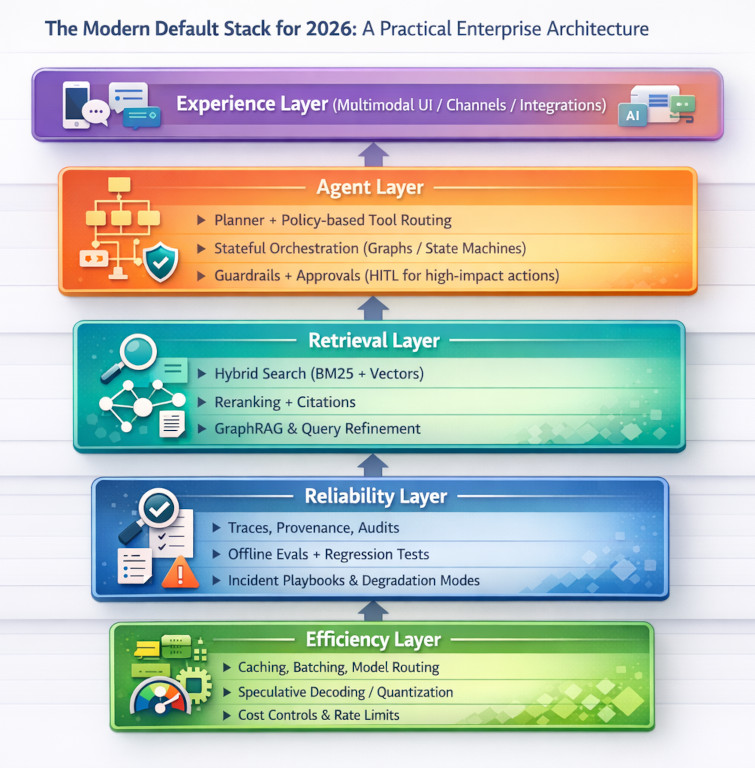 Where the industry is converging:
Where the industry is converging: