Conclusion
You don’t need a perfect MLOps platform to get value. Start with three moves that create immediate control and reduce incident risk:
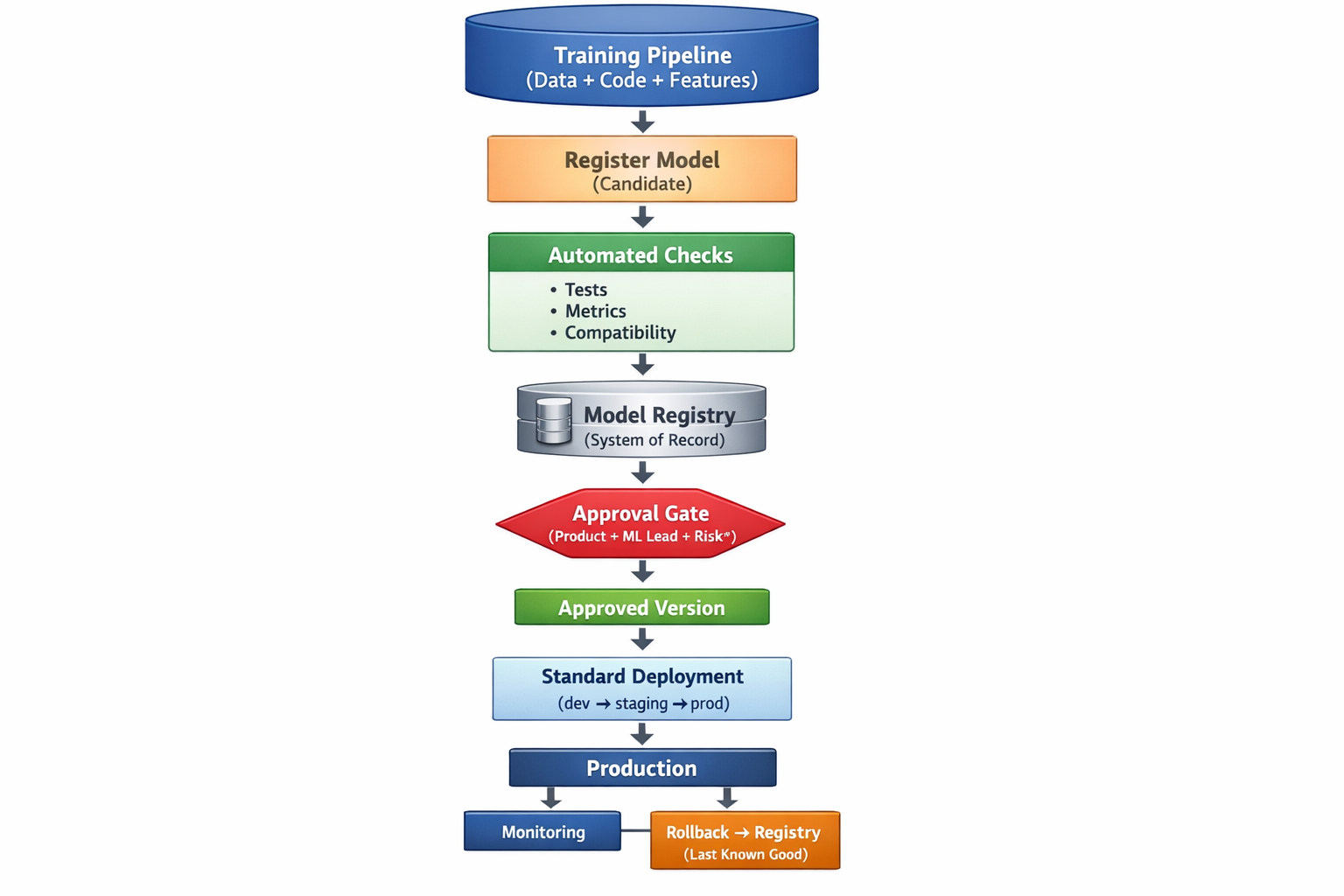
1. Make the model registry the gate for production promotion. If it’s not in the registry with the required metadata, it doesn’t ship.
2. Define minimum approval evidence. One standard evaluation summary, compatibility checks, and an owner sign-off.
3. Publish a rollback playbook and practice it. Revert to prior registered versions, define “known-good,” and rehearse traffic shifts.
What to measure over time
Release lead time: candidate → deployed
Rollback frequency: and what triggered it
Incident duration: MTTR for ML-related issues
Operational overhead: hours spent per release, per incident
Change failure rate: deployments that cause user-visible impact
If you can make releases repeatable, approvals lightweight, and rollbacks fast, you convert ML from a variable cost center into a predictable operational capability. That’s the language both CIOs and Finance understand—and it’s where release engineering pays for itself.
If your ML program is already influencing revenue, risk, or customer experience, then every “small model tweak” is a business change—whether it’s treated that way or not. The fastest way to reduce surprise costs is to stop shipping ML like an experiment and start releasing it like a product: registry-gated promotion, lightweight approvals, and a tested rollback path.
FAMRO-LLC Services helps enterprises implement this pragmatically—without boiling the ocean. We typically start with a focused, high-impact step:
Make your model registry the single gate to production (system of record for “what’s running”)
Put a rollback playbook in place (revert-to-known-good, controlled traffic shifts)
From there, we help you prove the value in business terms by tracking: release lead time, incident duration (MTTR), rollback frequency, and operational overhead per release—the metrics that translate directly into predictable spend and fewer production surprises.
If you’re ready to make ML releases auditable, repeatable, and cost-stable, FAMRO-LLC Services can assess your current ML delivery flow, identify the highest-risk gaps, and stand up a registry-driven release path that your CIO can govern and Finance can trust.
🌐 Learn more: Visit Our Homepage
💬 WhatsApp: +971-505-208-240