Reducing GPU Costs for Video Detection Workloads with AWS Batch and G6 Instances
Introduction
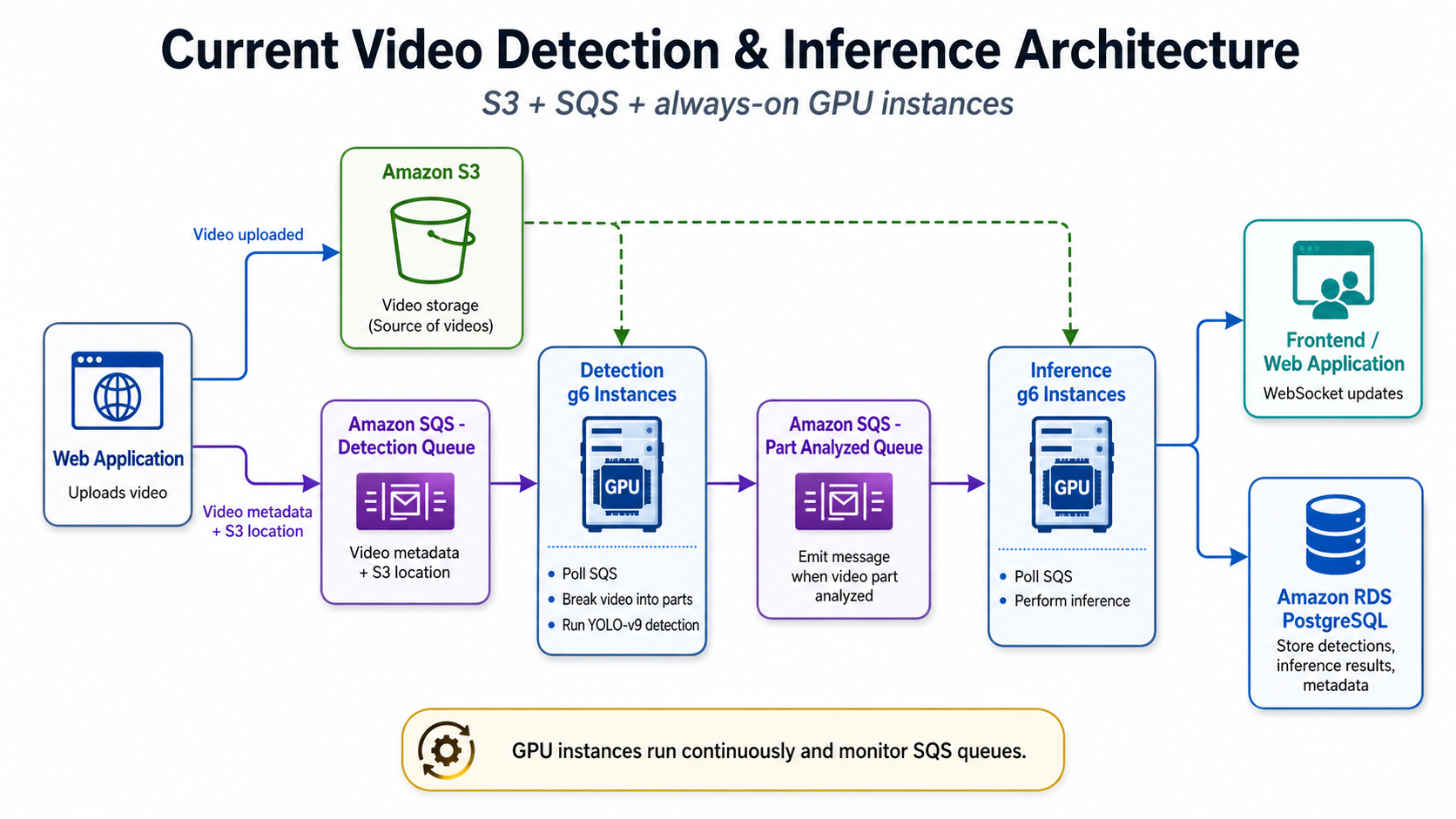
Video detection and inference workloads often require GPU-backed infrastructure, especially when using models such as YOLO-v9 for object detection, tracking, classification, and scene analysis. For organizations processing surveillance footage, uploaded evidence videos, traffic recordings, or incident-based media, GPU acceleration can be essential for performance.
However, not every video analytics workload needs real-time processing.
For many Law Enforcement Agency video workflows, the current process is still largely manual. Officers, investigators, or analysts may review CCTV recordings, uploaded case evidence, traffic footage, or bodycam and incident videos after an event has already occurred. In these cases, the business requirement is usually:
Process the video reliably and return useful results within an acceptable time window.
That is very different from:
Run inference in real time with sub-second latency.
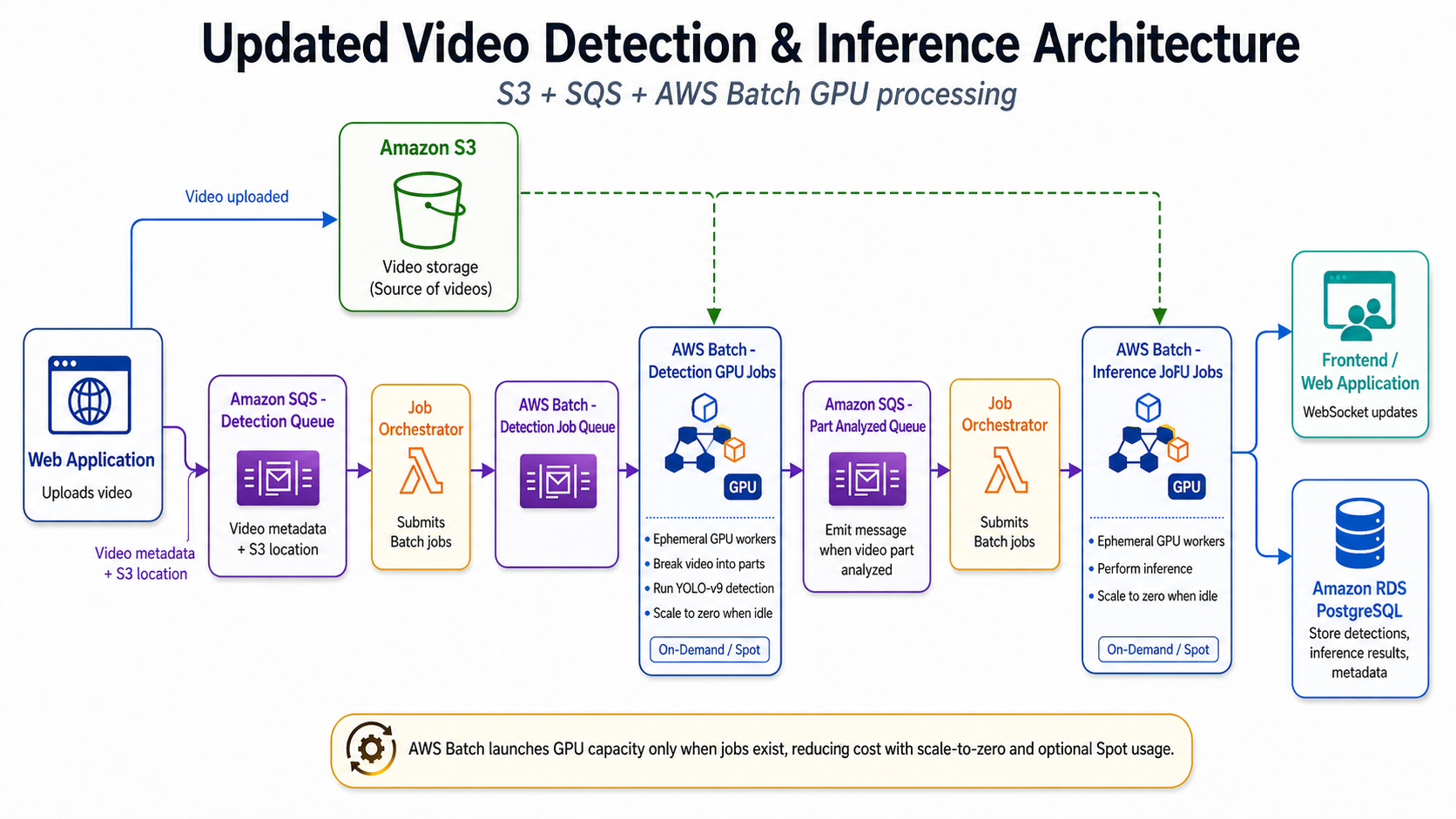
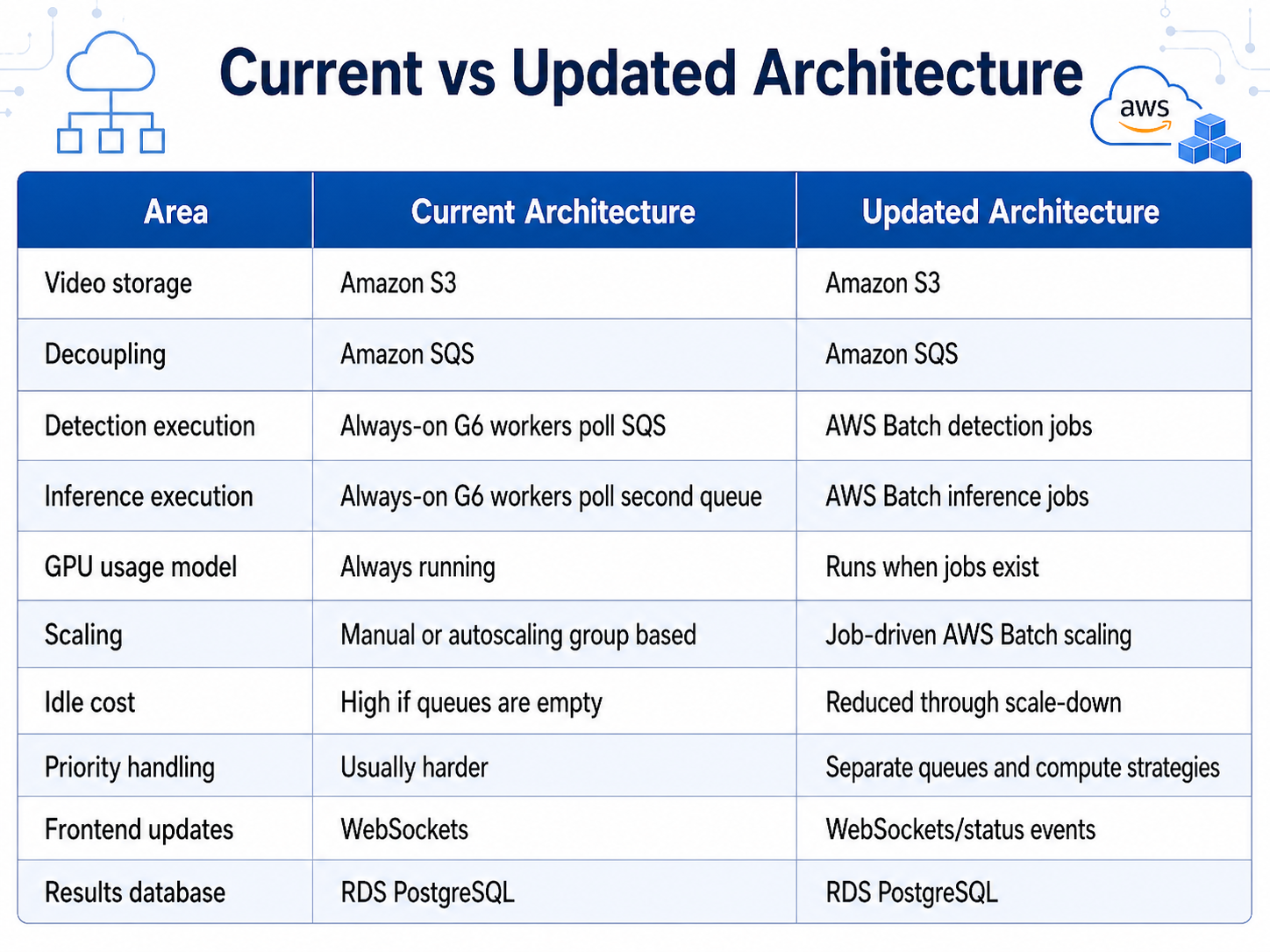
This distinction matters because it changes the cloud architecture—and more importantly, the cost model. When video processing can be asynchronous, organizations do not always need GPU instances running 24/7. Instead, they can use a job-based architecture where GPU capacity starts only when there is actual work to process.
AWS Batch, combined with Amazon EC2 G6 instances, Amazon S3, Amazon SQS, and containerized detection workloads, provides a practical way to reduce idle GPU spend without replacing the underlying ML model or rewriting the entire application architecture.