
Benchmarking Python vs Rust Performance for Common Use Cases
Introduction: Why Compare Python and Rust?
Python and Rust solve very different problems well, which is exactly why the comparison is useful.
Python has become the default choice for scripting, automation, internal tools, data workflows, APIs, and rapid product development. Teams choose it because it is easy to read, quick to write, and supported by a massive ecosystem. For small and mid-sized businesses, that often means faster delivery with fewer engineering hours.
Rust, by contrast, is designed for performance, memory safety, and predictable execution. It offers low-level control without the typical risks associated with manual memory management. That makes it attractive for systems programming, backend services under load, CPU-intensive pipelines, and components where efficiency matters.
For SMEs, the tradeoff is rarely academic. The real question is not “Which language is better?” but “Where does runtime efficiency justify extra implementation effort?” Performance benchmarking helps answer that with evidence. It gives teams a way to compare developer speed against runtime cost when workloads start to grow beyond what simple intuition can manage.
What Performance Benchmarking Measures — and Why It Matters
Performance benchmarking is the process of measuring how different implementations behave under controlled conditions. In this case, it means testing Python and Rust against the same workloads, with comparable inputs, and evaluating how each performs.
That matters because language reputation alone is not enough. Some tasks are dominated by raw loop performance. Others depend more on optimized libraries, memory layout, or startup overhead. In many real systems, the language itself is only one part of the result.
This comparison is focused on practical runtime behavior, not language advocacy. The goal is to understand how each option performs in common engineering scenarios and what those results mean in an operational setting.
A useful benchmark does more than record which implementation finishes first. It also considers:
- Memory consumption
- Throughput under repeated workloads
- CPU behavior
- Latency consistency
- Complexity of implementation
- Long-term maintainability
For SMEs, this broader view is essential. The fastest implementation is not always the best choice if it increases delivery time, onboarding friction, or maintenance burden without producing meaningful business value.
Key Metrics to Watch During Benchmarking
Before looking at any single use case, it helps to define the metrics that actually matter.
Execution Time
This is the most obvious benchmark metric. It measures how long a task takes from start to finish. For batch workloads, total runtime is often the first signal teams care about.
Throughput
Throughput measures how much work can be completed per unit of time. That could mean lookups per second, records filtered per second, or images processed per minute. It is often more useful than raw execution time when comparing scalable workloads.
Memory Consumption
Memory usage matters when processing large datasets or running multiple services on shared infrastructure. A faster implementation that consumes significantly more memory may not always be the better operational choice.
CPU Utilization
CPU behavior helps explain where time is being spent. Some workloads fully saturate available cores, while others are limited by memory access, interpreter overhead, or I/O. Watching CPU usage makes benchmark results more interpretable.
Latency Consistency
Average speed is useful, but consistency matters too. High variance can create unpredictable response times in user-facing systems or unstable processing windows in scheduled jobs.
Startup Overhead
This is especially relevant for scripts, CLI utilities, serverless workloads, and short-lived jobs. A language that performs well in long-running tasks may still be less attractive if startup cost dominates small workloads.
Implementation Complexity
This is often ignored in benchmark writeups, but it matters for business decisions. A solution that is twice as hard to build, test, and maintain may only be justified when the performance gain is material.
For SMEs, the right question is not only whether Rust is faster than Python. It is whether the performance difference is large enough to justify the additional engineering and operational cost.
Use Case 1: Exact String Lookup in a Large Collection
A common real-world workload is exact string lookup against a large in-memory dataset. This appears in caching layers, deduplication systems, access control checks, fraud rules, reference matching, and many internal tools.
For this benchmark, assume we load 1 million strings into memory and perform 10,000 searches across a mix of keys that exist and keys that do not. The goal is to compare the efficiency of standard hash-based lookup structures in both languages.
In Python, the natural choices are set and dict. In Rust, the equivalents are HashSet and HashMap.
Python Example
import random
import time
NUM_STRINGS = 1_000_000
NUM_SEARCHES = 10_000
values = [f"key_{i}" for i in range(NUM_STRINGS)]
lookup_set = set(values)
lookup_dict = {v: True for v in values}
search_keys = [
f"key_{random.randint(0, NUM_STRINGS - 1)}" if i % 2 == 0
else f"missing_{i}"
for i in range(NUM_SEARCHES)
]
start = time.perf_counter()
found_set = sum(1 for key in search_keys if key in lookup_set)
set_duration = time.perf_counter() - start
start = time.perf_counter()
found_dict = sum(1 for key in search_keys if key in lookup_dict)
dict_duration = time.perf_counter() - start
print(f"Set found: {found_set}, time: {set_duration:.6f}s")
print(f"Dict found: {found_dict}, time: {dict_duration:.6f}s")
Rust Example
use std::collections::{HashMap, HashSet};
use std::time::Instant;
fn main() {
let num_strings = 1_000_000;
let num_searches = 10_000;
let values: Vec<String> = (0..num_strings)
.map(|i| format!("key_{}", i))
.collect();
let lookup_set: HashSet<String> = values.iter().cloned().collect();
let lookup_map: HashMap<String, bool> = values
.iter()
.cloned()
.map(|v| (v, true))
.collect();
let search_keys: Vec<String> = (0..num_searches)
.map(|i| {
if i % 2 == 0 {
format!("key_{}", i % num_strings)
} else {
format!("missing_{}", i)
}
})
.collect();
let start = Instant::now();
let found_set = search_keys
.iter()
.filter(|key| lookup_set.contains(*key))
.count();
let set_duration = start.elapsed();
let start = Instant::now();
let found_map = search_keys
.iter()
.filter(|key| lookup_map.contains_key(*key))
.count();
let map_duration = start.elapsed();
println!("Set found: {}, time: {:?}", found_set, set_duration);
println!("Map found: {}, time: {:?}", found_map, map_duration);
}
Discussion
This benchmark typically favors both languages’ hash-based structures for lookup speed, but the implementation tradeoff is still meaningful.
Python usually makes this kind of workload trivial to express. That matters when the lookup layer is just one part of a larger application and the performance is already acceptable.
Rust is likely to offer tighter memory control and faster execution in large-scale or repeated lookup workloads, especially when integrated into a long-running service. But for many SMEs, the key question is whether the speed difference affects a real outcome such as API latency, batch completion windows, or infrastructure sizing.
Use Case 1: Comparing Python vs RUST performance
The first benchmark measures exact string lookup against a large in-memory dataset. In the article, this use case is framed as loading 1 million strings and running 10,000 searches using hash-based structures: set and dict in Python, and HashSet and HashMap in Rust.
Statistics Table: For Python Set & RUST Hashset lookups
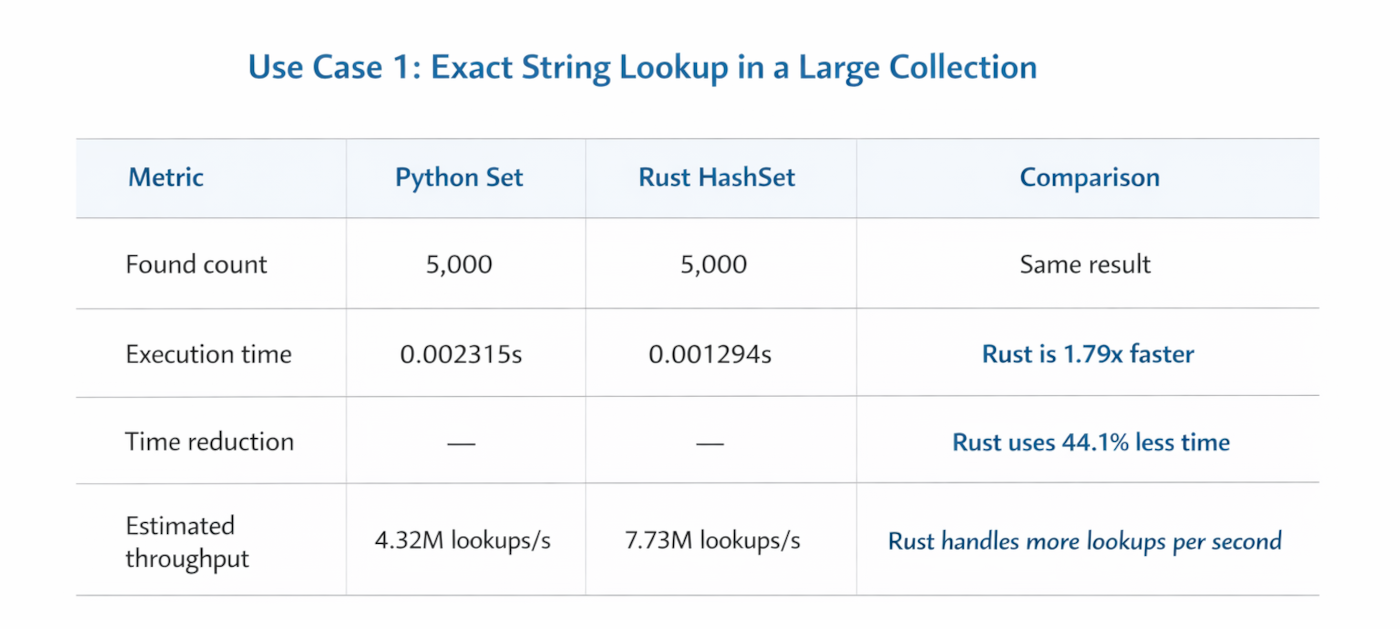
Discussion of the statistics
This is the cleanest comparison of the two use cases because both implementations return the same number of matches. Rust performs better in both lookup structures, with the biggest gain appearing in the map/dict comparison. That supports the article’s broader point that Rust can deliver tighter runtime performance in repeated, hash-based workloads, especially when these lookups happen frequently inside long-running services.
At the same time, Python’s numbers are still very strong in absolute terms. Finishing 10,000 lookups in roughly 2.3 milliseconds means Python may already be “fast enough” for many internal tools, APIs, and business workflows. For SMEs, the practical question is not whether Rust wins the benchmark, but whether that speed difference changes API latency, infrastructure cost, or throughput in a meaningful way.
Use Case 2: Image Manipulation Workloads
Image processing is a useful benchmark category because it stresses CPU cycles, memory movement, and library efficiency all at once.
For this scenario, consider resizing 100 images from 4K to 1080p. This is representative of media pipelines, e-commerce catalog processing, content moderation systems, thumbnail generation, and automated publishing workflows.
Here the comparison is not just between Python and Rust as languages. It is also between their library ecosystems. In Python, common choices include Pillow and OpenCV. In Rust, common options include image and fast_image_resize.
Python Example with Pillow
import os
import time
from PIL import Image
INPUT_DIR = "input_images"
OUTPUT_DIR = "output_images"
TARGET_SIZE = (1920, 1080)
os.makedirs(OUTPUT_DIR, exist_ok=True)
start = time.perf_counter()
for filename in os.listdir(INPUT_DIR):
input_path = os.path.join(INPUT_DIR, filename)
output_path = os.path.join(OUTPUT_DIR, filename)
with Image.open(input_path) as img:
resized = img.resize(TARGET_SIZE, Image.Resampling.LANCZOS)
resized.save(output_path)
duration = time.perf_counter() - start
print(f"Processed 100 images in {duration:.4f}s")
Rust Example with image Crate
use std::fs;
use std::path::Path;
use std::time::Instant;
use image::imageops::FilterType;
fn main() {
let input_dir = "input_images";
let output_dir = "output_images";
let target_width = 1920;
let target_height = 1080;
fs::create_dir_all(output_dir).unwrap();
let start = Instant::now();
for entry in fs::read_dir(input_dir).unwrap() {
let entry = entry.unwrap();
let path = entry.path();
if path.is_file() {
let img = image::open(&path).unwrap();
let resized = img.resize(target_width, target_height, FilterType::Lanczos3);
let output_path = Path::new(output_dir).join(path.file_name().unwrap());
resized.save(output_path).unwrap();
}
}
let duration = start.elapsed();
println!("Processed images in {:?}", duration);
}
Discussion
This is a good example of why language-only benchmarking can be misleading.
In image manipulation, the underlying library often determines a large share of the outcome. A Python workflow that delegates core processing to highly optimized native code may perform far better than expected. Likewise, a Rust implementation can benefit from efficient memory handling and lower orchestration overhead, but actual gains depend heavily on the specific crate and image pipeline design.
For SMEs, this matters because media workflows often scale quickly. A small image-processing task can become a bottleneck once volume increases across catalogs, user uploads, or marketing assets. If processing time directly affects publishing speed, infrastructure cost, or customer experience, benchmarking is worth doing with production-like images and library choices.
Use Case 2: Comparing Python vs RUST performance
This benchmark compares resizing 100 images from 4K to 1080p. The article correctly notes that this use case is shaped not only by the language runtime, but also by the image-processing libraries being used. In this case, the Python implementation uses Pillow and the Rust implementation uses the image crate.
Statistics Table: For Image Manipulation with Python & RUST
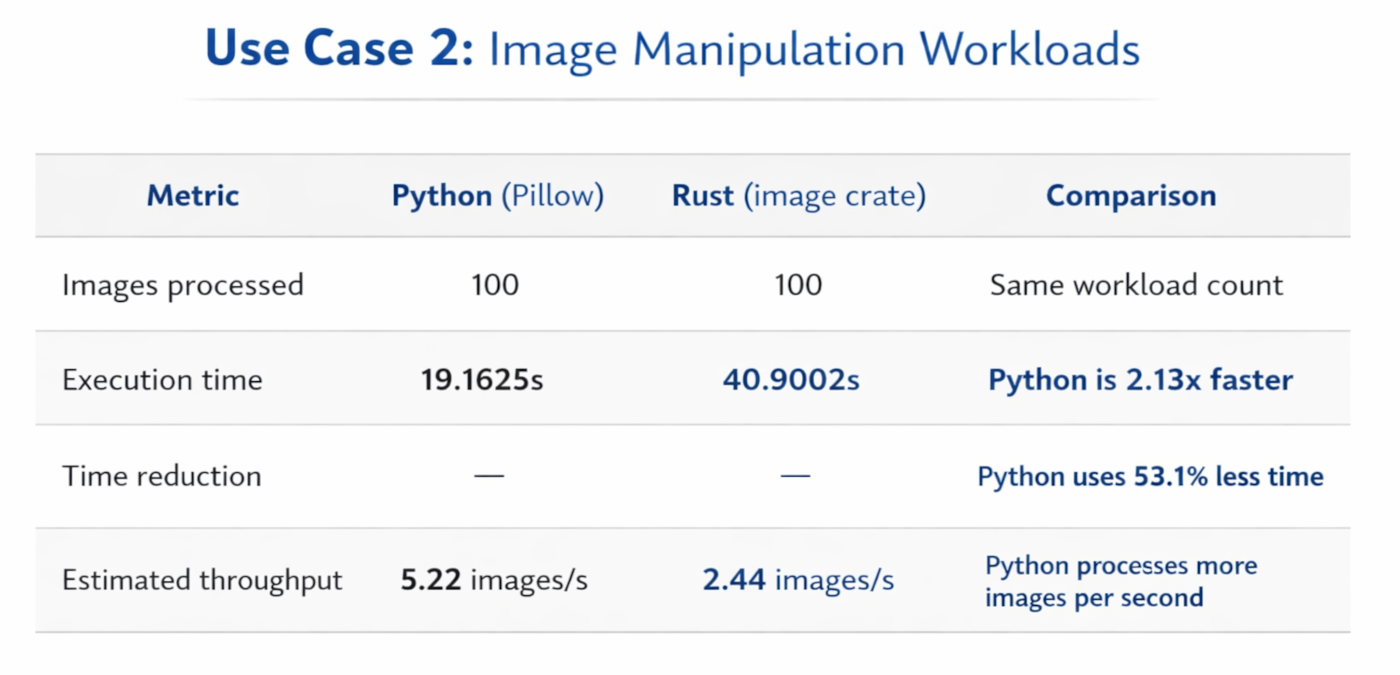
Discussion of Statistics
This result is a useful reminder that benchmarking is not purely about language syntax or compiler performance. In this implementation, Python clearly wins the image-resizing test, finishing the same 100-image workload in less than half the time taken by Rust. That is fully consistent with the article’s warning that optimized native libraries can dominate the result, sometimes allowing Python to outperform expectations in CPU-heavy media tasks.
The takeaway here is not that Python is always better for image processing, or that Rust is weak in media pipelines. The more accurate conclusion is that library selection and implementation details matter enormously. For production decisions, this benchmark category should ideally be repeated with alternative Rust libraries such as fast_image_resize, and with production-like image sets, before drawing broad conclusions about end-to-end performance.
Results and Discussion Across the Two Use Cases
Looking at the two comparable benchmarks, the pattern is not that one language dominates in every scenario. Instead, the results show that performance is closely tied to workload type and implementation details. Rust clearly performs better in the exact lookup benchmark, where low-level efficiency and hash-based operations shine. Python, however, performs better in the image-processing benchmark in this implementation, showing that mature native-backed libraries can significantly influence real-world outcomes.
This supports the broader point of the article: the practical choice is not about declaring Python or Rust universally faster, but about understanding where the performance gap is meaningful enough to justify the trade-offs. For SMEs and startup teams, benchmark results matter most when they translate into business value such as lower compute cost, faster processing pipelines, or better responsiveness in production systems.
The right interpretation for SMEs depends on context:
Team familiarity: Python is usually easier to hire for and faster to onboard.
Debugging and iteration speed: Python often reduces development friction.
Deployment model: Rust can be appealing for lightweight binaries and predictable runtime behavior.
Optimization cost: Rewriting code in Rust only makes sense when the gain solves a real problem.
Business impact: Performance improvements matter most when they reduce infrastructure spend, shorten processing windows, or improve user-facing responsiveness.
Benchmark data becomes valuable only when linked to business outcomes. A 20 percent speed gain may not matter at all in a nightly batch job with plenty of buffer time. The same gain could matter a lot in a latency-sensitive API or high-volume processing service.
Conclusion
Python and Rust are not competing for every part of the same system. In many cases, they are better viewed as complementary tools.
Python remains a strong choice for fast delivery, broad ecosystem support, automation, analytics, APIs, and internal platforms. It is often the right default when speed of development matters more than raw runtime efficiency.
Rust becomes compelling when the workload is performance-critical, resource-constrained, or large enough that execution cost starts to affect operations. It is especially worth considering for CPU-heavy paths, high-volume processing, low-latency services, and components where predictable performance matters.
For SMEs, the best decision framework is practical:
Build quickly where productivity creates the most value. Measure real bottlenecks. Optimize only where the evidence shows that performance has become a business issue.
That is the real value of benchmarking. It replaces assumptions with data and helps teams invest engineering effort where it will actually move the business forward.
🌐 Learn more: Visit Our Homepage
💬 WhatsApp: +971-505-208-240